This column explores why we have waiting time between different steps in the software development life cycle and what we can do to eliminate them and iterate quicker – going from idea to execution to insight in less time and finding PMF faster.

What’s the slowest part of software development?
Many would say engineering or perhaps design. But how do we even know this? Do we even track all the parts of the process? Which of the following activities gets estimated and tracked on a task by task basis?
It’s funny that development is only one piece of the complete work cycle yet it is the only one we obsessively track in JIRA tickets and force granular estimations out of. The only one we track velocity on and have retrospectives about.
We ask for engineers to estimate and account for the time it will take them to fix bugs they haven’t even made yet in the form of buffers. Yet I’ve never seen a product manager asked to give an estimate on the number of meetings they will attend and emails they will write to finish a quarterly roadmap. This is not to insinuate PMs are in the wrong here, it’s just how things have traditionally worked.
What’s really interesting though is that in a typical four to six month cycle between initial idea and completed analysis, the biggest culprit is not engineering, design, analysis or even executive offsites. The biggest time suck is invisible. It is waiting.
This post explores why we have waiting time between different steps in the software development life cycle and what we can do to eliminate them and iterate quicker – going from idea to execution to insight in less time and finding PMF faster.
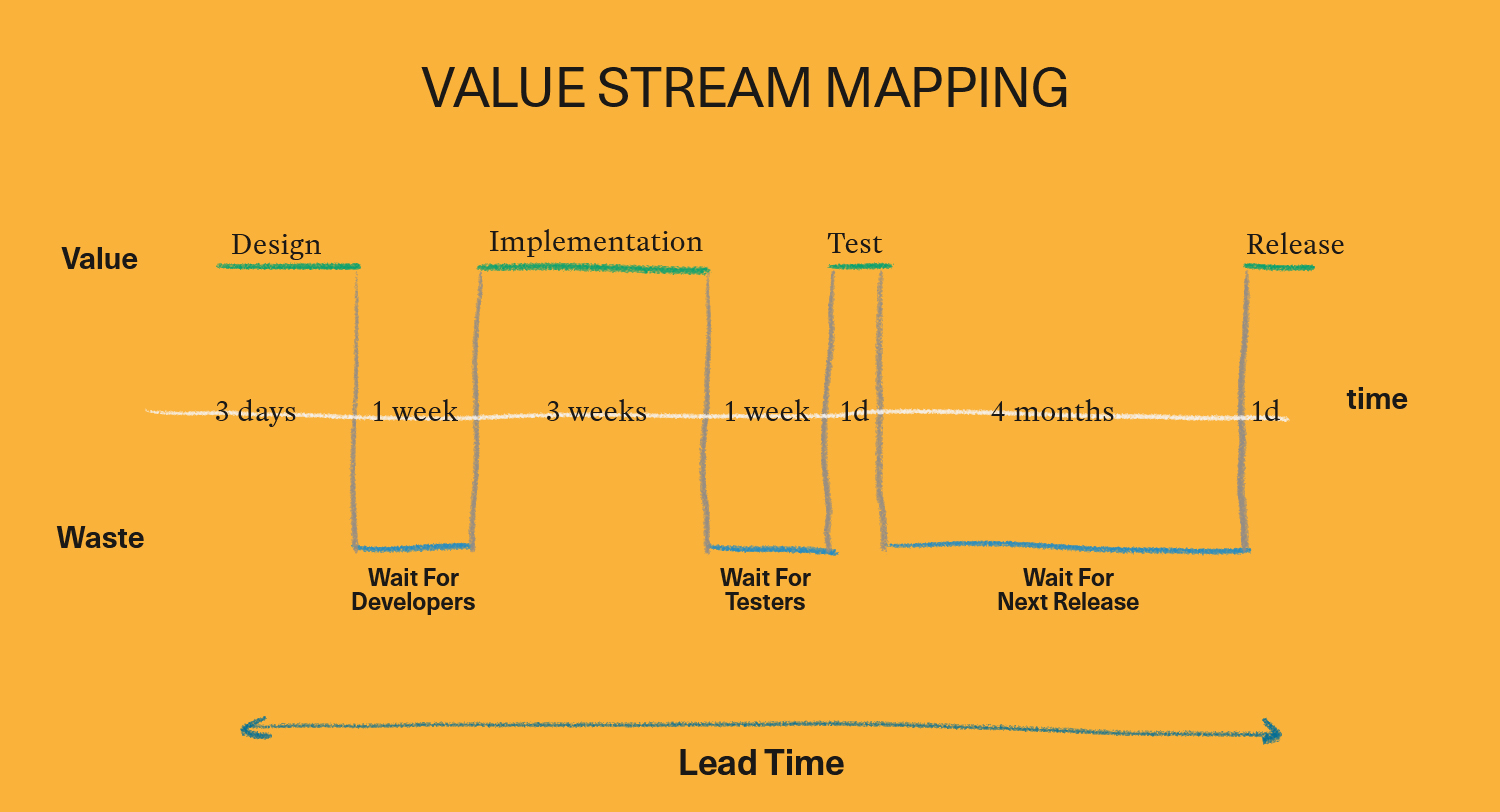
As described in my earlier post on Be Wrong Faster, startups are complex environments (full of unknowns) where we need to optimize for learning. Being efficient is useless if we aren’t frequently releasing, learning and iterating on what we’ve learned.
It’s not about how long we spend on any one activity (efficiency), it’s about how long it takes for us to go from idea to insight (calibration). And much of this time is spent waiting.
Think about where waiting happens right now in your organization. Here are a few common culprits. Waiting for:
– A staging machine to be available
– A campaign to complete so I can send more notifs
– Code to get reviewed
– Designs to be finalized
– Waiting for a new dashboard
– The engineer who wrote the code to debug it
– An executive to approve a budget
– Other teams to finish so we can release
All of these are basically examples of resource imbalance. That’s a fancy way of saying “we’ve got more work for a particular function / machine than we’ve got people / machines to do it.
Resource imbalance and its effects
A typical development process is: “Product manager decides what to build” → “Designer designs the flow and screens” → “Developer builds the screen”.
If a developer is waiting for design to be finished, maybe we have too many developers for the amount of designers in the organization.
Many of these are unavoidable. But many can be mitigated. And unfortunately the common reaction to these issues is to create a vicious cycle which exacerbates them.
The vicious WIP / resource imbalance cycle
At the heart of it, Agile Software Development is simply the practice of executing work in small batches, measuring the impact quickly, and then starting a new batch with that new information. It is quite simply optimizing for learning.
One of the biggest mistakes organizations make as they scale is they try to optimize for utilization. That’s a fancy way of saying “keeping everyone busy.”
Say a company is building a new home screen. The work can’t start until the design is at least somewhat complete. So in the scenario where our developers are waiting on a design, what do most teams do? The developers start working on the code for the next feature we have planned or even worse, start working for another team. This sounds good in theory, but then what happens when they are 25% through that and the designs come through?
They have to context switch back to the home screen project, or there is a conflict between teams.
Another example is when teams get slow because they are “waiting for a code review”? This is happening because the engineer who could review your code is now busy on another project they committed to. Everyone is busy, but nothing is getting done.
More WIP = more wait times and more context switches.
How to streamline and serialize
X-functional teams: The first step is to resource fully dedicated x-functional teams to products and keep those boundaries fairly rigid. There’s a huge cost to “borrowing” engineers between products. Avoid horizontal teams like “Mobile” and “QA”, instead try to build product or at least user journey focused teams like “onboarding”, “checkout”, etc which are fully x-functional. If you don’t, you’ll end up with a scenario like below:

Visualize the value stream: The second step is to correctly visualize and measure the value stream (where delays happen) so that it’s obvious where the constraints are. This could be as simple as a standup, or as complex as a Kanban board.
Don’t have too many specialists: The third step is to limit specialization. In the Google Search Index team, let’s say we have a database indexing engineer. They may be 25% utilized most of the time, but during a big update, there might be demand for 400% of their time. This slows the entire project while the rest of the team waits on them. A forward thinking manager would ensure that another engineer with similar skills (a background in caching or encryption) would x-train so they are able to do some of the indexing engineer’s work.
Allow for slack in the system: Slack is incredibly important for agility. Imagine a highway with four lanes where every car is going exactly 70km/h and all cars are three metres apart. This is optimum efficiency. We are using all the space available and the maximum number of people are going the maximum speed.
What happens when someone needs to change lanes to get to their exit?
What about an accident?
What if someone is driving 50 km/h in one lane?
This is why we need slack. Traffic jams don’t happen because there are too many cars – traffic jams occur because there is variance, and not enough slack in the system to account for it.
So instead of starting on the next “critical project”, have a list of nice-to-haves which can be quickly done on the side to promote efficiencies, keeping your people ready to review that code, make that configuration change or deploy that new hotfix.
Start Less, Finish More
Here are some things you can start right now to put this theory into practice:
- Start tracking lead time, and focus less on effort estimates. Lead time is simply the time it takes from inception of a project to completion. This is not the same as an effort estimate. The lead time to get a passport for instance might be four weeks, the effort to fill the paperwork and people to process your paperwork might be two hours. The lead time to prepare a meal might be 30 minutes while four people are working a total of two hours.
- Look at your pull request statistics. An easy first target is how long code sits waiting for reviews. I made a little script for this: Pull Review Statistics
- Build your slacklog. Resist the temptation to start multiple projects by building a list of projects which people can work on while they are waiting.
- Start the All Team Test. The worst culprit for wait times is throwing it over the fence to QA. If you don’t have great test automation, consider the All Team Test. I speak about it here (2min video).
Good luck and please get in touch if any of this is helpful for you or if you have a difference of opinion! I’m available on Twitter.