
(x-post from https://jacobsingh.substack.com/p/how-to-start-a-product-engineering)
As startups evolve, their org structures must evolve to match the evolving needs of the company. Cross-functional product teams give way to matrixed shared services teams w/ and eventually to internal product orgs aka “platform teams”. This article will specifically focus on best practices for building platform teams.
This post (like the rest of this blog) comes from coaching sessions I do with tech leaders. This week’s session was with Dhruv Baldawa of Paystack. If you’ve got a product engineering leadership question you’d like to bounce around with me, I do one free one every week for this newsletter. Just fill the form.
Subscribe to receive new posts weeklyish on product engineering leadership. No other emails. Max 4 a month.✓
Jumping in.
Background:
- Dhruv is a Principal Engineer at Paystack, the leading African payment gateway.
- The tech team is 100 people (out of 250 employees).
- He will soon be leading the newly formed platform group.
The question:
- How should we best structure the org at this scale for reliability and scalability (not just product features)?
- How can I create a technical strategy that aligns to the business strategy?
- What are best (and worst) practices for building a platform team?
Session details:
From a CTO/Tech org lens, I like to think of the startup journey in 4 broad phases:
- The scramble: x-functional teams purely chasing Product Market Fit (PMF) with little regard to maintenance or architecture. Optimizes for speed by doing only a few things at once and throwing everyone at the problem. High degree of flexibility and generalization (few specialists).
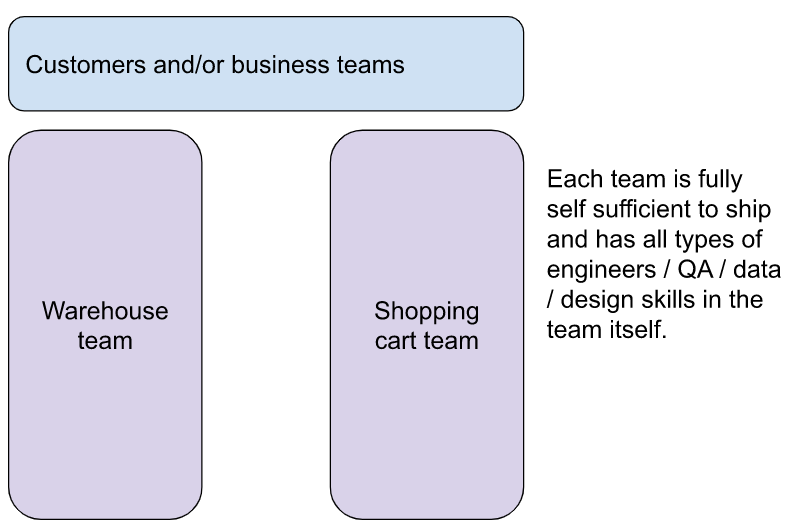
- Adult supervision: Strategic alignment becomes an issue, as does quality when we scale. We start hiring specialists (e.g. mobile, QA, data engineering, etc). These specialists often are a bottleneck because multiple teams use them. Teams depends a lot on each-other (poor architectural boundaries) and we add EMs, PMs, etc to manage this “resource utilization” and end up with a lot of planning meetings, often Scrum or something scrumish is instituted to ensure communication happens. [ Longer post about exactly this over at Sequoia Cap ]. People start coming to work just for free coffee.
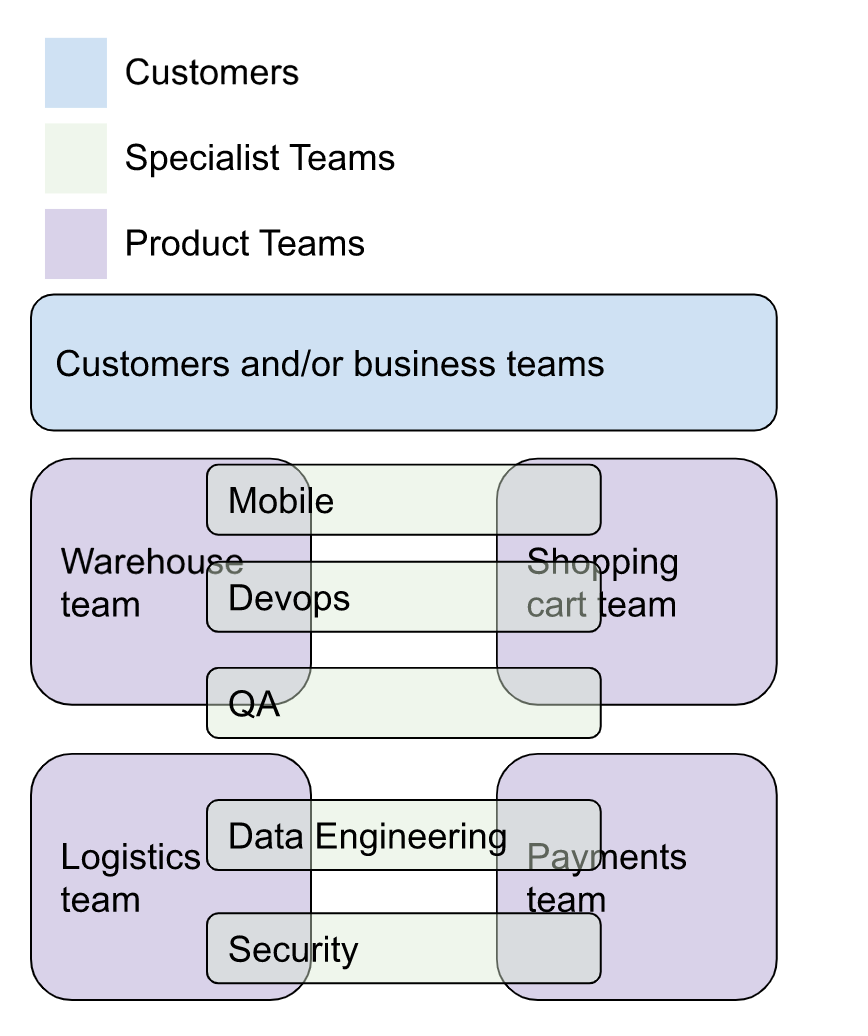
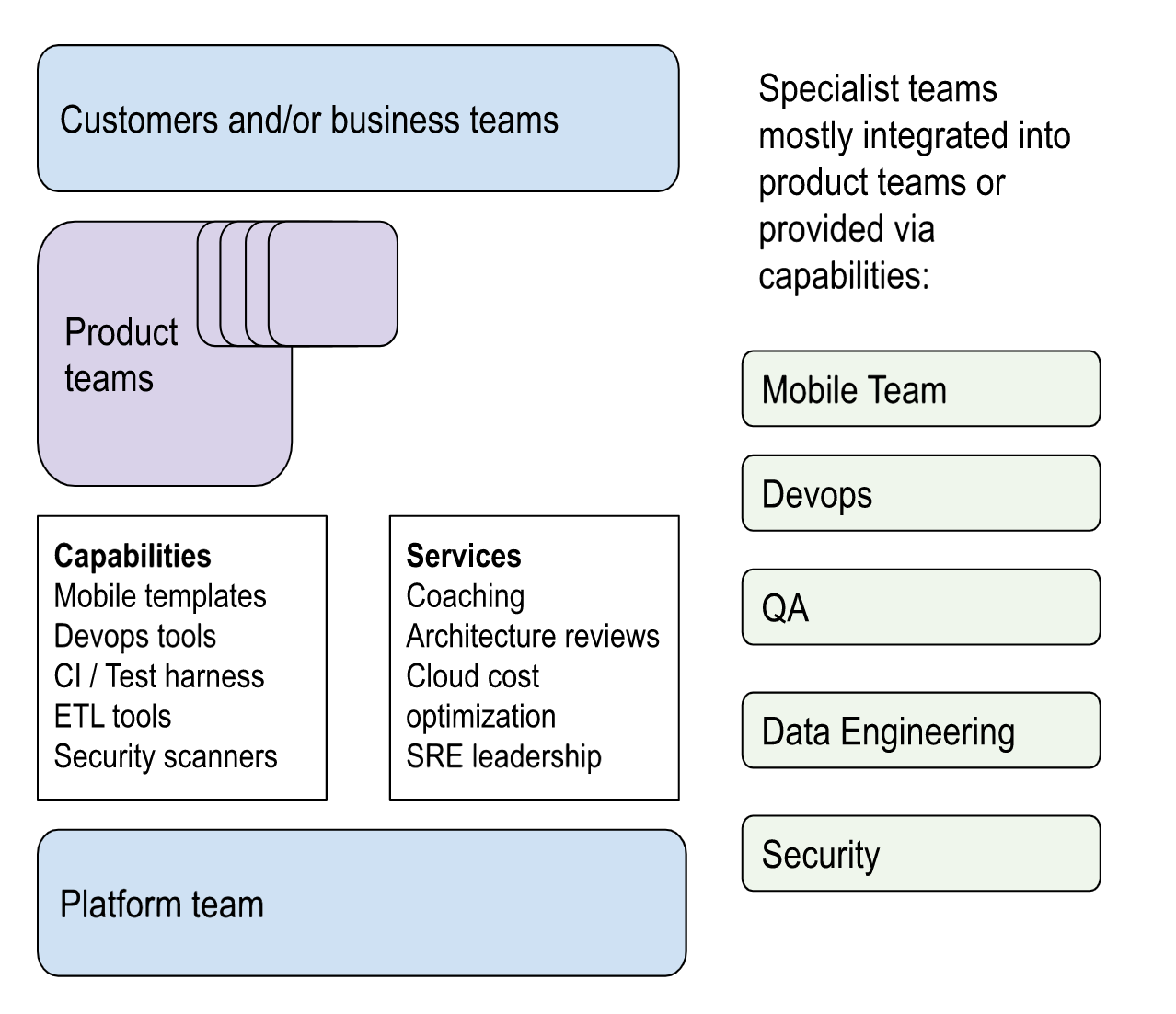
- Platform teams: The bureaucracy and slowness of the “Adult Supervision” phase becomes unbearable and the product teams never maintain systems or automate anything. Platform teams are created to remove dependence on experts (e.g. a platform team integrates an ETL tool, removing a bottleneck on data engineering). In essence, these are teams which are building products for the people who build products. We can call these products “capabilities" as seen below (partial list):
- Independent business units: Even with automation and platform teams, the org gets too large for a single leader to manage and it starts hiving off into different business lines, separate P&L responsibility, etc.
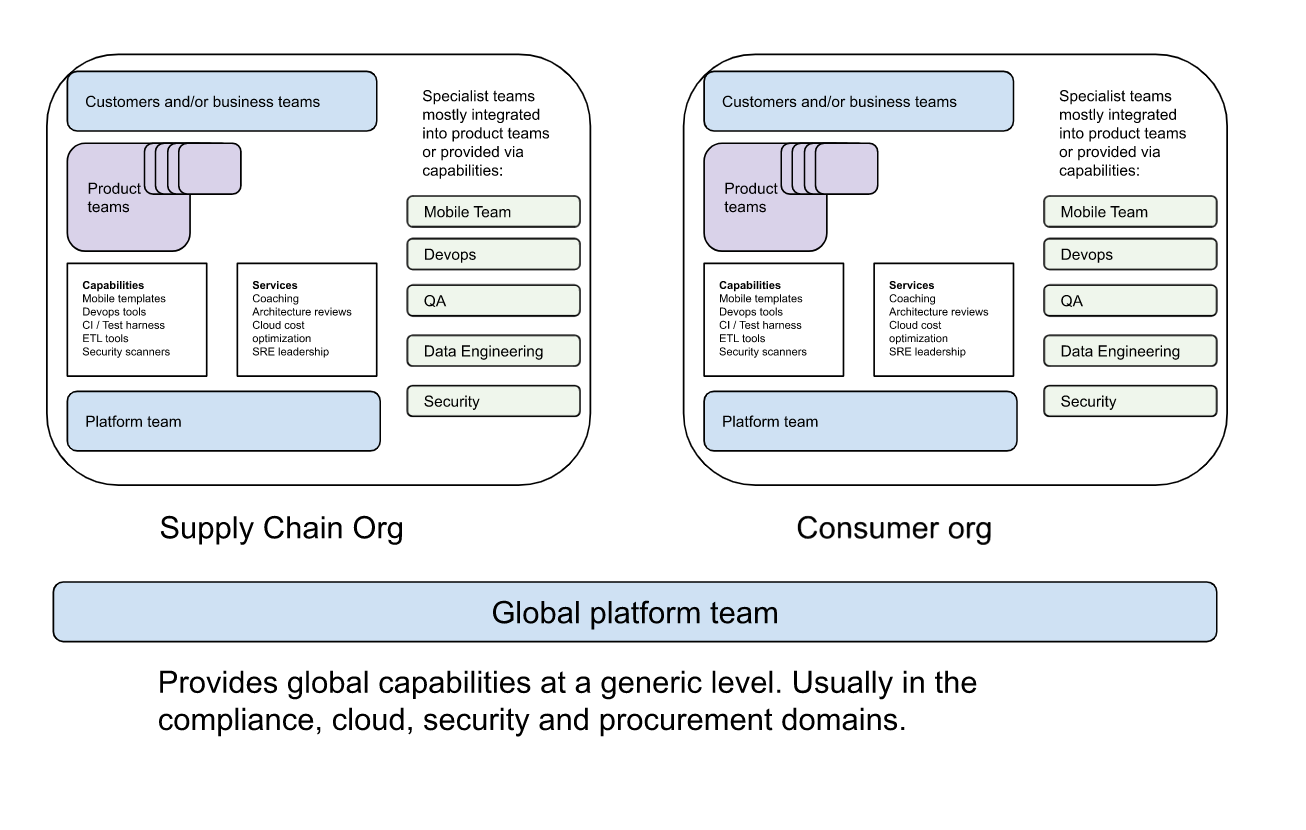
Although this progression deserves a longer post in itself, I’m going to dig into phase 3 (platform teams).
Why platform teams?
Dhruv put the problem well, when he said:
“Everyone is milking the cow, but no one is feeding it or giving it water”
What he means is that the product teams are responsible for business outcomes (e.g. payments, shopping cart, administration, lending, etc). But no one is responsible for any particular code base, least of all the generalized ones (such as an API gateway or a transaction database). In addition, no one is responsible at all for non-functional requirements like scalability, security, reliability, etc. The org wants to address this by forming a platform team.
He’s seen platform teams fail because they are out of touch with the teams they serve, or they are starved of influence / budget or they fail to make meaningful changes on any reasonable time frame so is curious to discover what the best practices are to avoid this.
Let’s dig into what platforms do and some best practices on how to run them.
The ideal platform team is a product team:
We defined earlier that platform teams are product teams which build products that help the actual product teams build things for customers. This is a gross generalization, but it’s a useful metaphor since it correlates with many things we know about why product teams go south.
Distribution is more important than product: Engineers have been complaining about poor debugging capabilities. The platform team comes in and integrates a log aggregation service and a request tracing and search tool. Amazing. Only problem is, the garbage log messages sprinkled across 20 microservices make it impossible to use. Now you need all those engineers who were clamoring for this capability to go through and audit all of their log messages. Where do you think this falls in the product backlog? Fucking nowhere, - that’s right.
A good platform team considers this and only attempts products they have broad support for politically (boss says so) or are easy to build grassroots support for through incremental progress. Always consider distribution as the primary hindrance to success, not how useful or how easy it is to build something.
Connect the dots: When planning a “tech roadmap” or “engineering roadmap” as distinct from a “product roadmap”, it’s super important that you have some tangential connection to your company strategy. For instance, if your strategy is to be the “bank with the best customer service”, then investing in an automated ETL pipeline for customer data makes sense so your CRM team has up to date information. Sure, it also means the CRM team stops bugging your engineers, but you should be able to connect the dots for the CEO too and be defensible. Here’s a template which might help.
Priority is a singular noun: Many force multipliers in engineering don’t have any benefit unless you have 100% adoption. For instance, let’s say you want to use a more modern CI system which allows you to stage hotfixes and the old one doesn’t support it. This requires every single micro-service to update its Ansible/Puppet/k8s/whatever build file. If even one service isn’t done, then all this work adds no value. Teams will often give an arbitrary “20% to engineering work” as a concession. This is a terribly broken model, because 80% of the work is happening at low efficiency, and if the 20% isn’t crossing the finish line on a project, it’s just making the project take longer because of context switching and shifting baselines.
So when a project requires 100% compliance to be effective, get a mandate from above, stop everything (within reason) and just get the SOB done in a week. Trust me, nothing is that hard when everyone is mobbing it.
Build in the public, be a plumber coach: That being said… most projects do add value without getting 100% done. So most of the time, your job as a platform team is to be a janitor, not an architect. Staying in touch with deployments, on-calls, onboarding, migrations, etc and unblocking people is the primary work. When you’ve served them, only then will they listen to you as you try to push for new standards.
Keep weekly or bi-weekly demos / emails going out, run lunch and learns, facilitate post-mortems, and ensure engineering problems get the right visibility. This requires that you also understand the product roadmap and are willing to get your hands dirty with operational concerns too.
Rotate. It’s crucially important that you don’t let people stay in product or platform teams forever. Folks should be shifted around either on a rotational basis or longer-term. That does not mean having one person half in either team, but perhaps doing a quarter in the platform team once a year or moving after a year in product makes sense. The reverse is also true. Failure to do this will ensure Conway’s law trips up your best laid plans.
The takeaway (1m):
Wrapping up and other ideas:
I hope this post has helped you think about how to structure your engineering platform teams. It’s a super interesting topic and I could have written another 2k words here. Specifically, I’d love to explore:
- Different execution models of platform projects
- Service design and domain boundaries in software architecture
- Framework and product release cycles and dependencies
- Education and inclusion of non-technical staff in platform team priorities.
- Design, product, analytics and other specialist platform teams.
If there’s anything you’d like to share on the above or additional questions you want to dig into, please leave a comment on twitter and/or fill out my weekly free coaching session form.


